
プレスリリース
rinnaは日本語の音声処理に適した事前学習モデルwav2vec 2.0・HuBERT・data2vecを開発し、商用利用可能なApache-2.0ライセンスで公開したことをお知らせします。
■ rinnaのモデル公開活動
rinnaは、日本語の処理に適したGPT・BERT・HuBERT・CLIP・Stable Diffusionなど、テキスト・音声・画像に関する事前学習済み基盤モデルを公開してきました。2021年4月からrinnaが公開してきたモデルのダウンロード数は累計550万を超え、多くの研究・開発者にご利用いただいています。
日本語の音声処理のための音声基盤モデルとして、2023年4月には日本語音声コーパスReazonSpeech v1を用いてHuBERT Baseを学習し、事前学習済みモデルを一般に公開しました。そしてこの度、より多くの選択肢を提供するために、新たにwav2vec 2.0 Base・HuBERT Large・data2vec Audio Baseの3つの事前学習モデルを学習し、Hugging FaceにApache-2.0ライセンスで公開しました。音声表現が学習された事前学習モデルの公開が、日本のAI研究・開発の更なる発展につながることを願っています。
・日本語wav2vec 2.0 Base (rinna/japanese-wav2vec2-base) : https://huggingface.co/rinna/japanese-wav2vec2-base
・日本語HuBERT Large (rinna/japanese-hubert-large) : https://huggingface.co/rinna/japanese-hubert-large
・日本語data2vec Audio Base (rinna/japanese-data2vec-audio-base) : https://huggingface.co/rinna/japanese-data2vec-audio-base
■ rinnaの日本語音声事前学習モデルの特徴
・wav2vec 2.0 Base・HuBERT Base (2023年4月に公開)・HuBERT Large・data2vec Audio Baseの4種類から利用目的に適したモデルを選択できます。
・全てのモデルは、約19,000時間の日本語音声コーパスReazonSpeech v1を用いて学習されています。
・Hugging Faceに商用利用可能なApache-2.0 Licenseで公開されています。
・事前学習モデルを活用することで、音声認識や音声合成などのタスクに応用することができます。
・日本語話し言葉コーパス (CSJ) を用いて、日本語音声認識タスクの実験を行いました。各事前学習モデルに対して、日本語の音素をターゲットとしたCTC損失による教師あり学習を行い、単語誤り率(WER、低い値ほど高スコア)を算出しました(図1)。実験結果より、各モデル構造で英語の音声データから学習した事前学習モデルよりも、日本語の音声データから事前学習したrinnaモデルが高いスコアを示すことが確認できました。
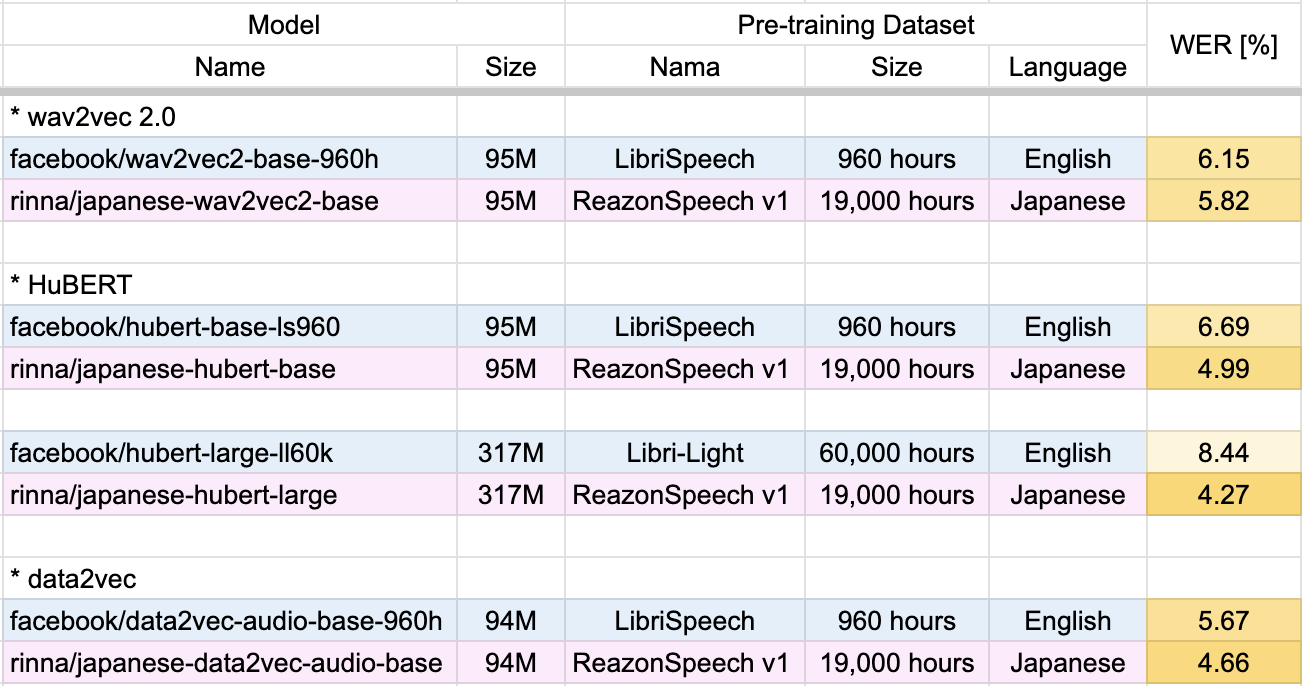
図1: 日本語音声認識結果
■ 今後の展開
rinnaの研究チームが開発する大規模な事前学習モデルは、すでに当社の製品に広く利用されています。AIに関する研究・開発を続け、より高性能な製品を開発していきます。また、他社との協業も進め、AIの社会実装を目指します。
※文中の社名、商品名などは各社の商標または登録商標である場合があります。